Our blog











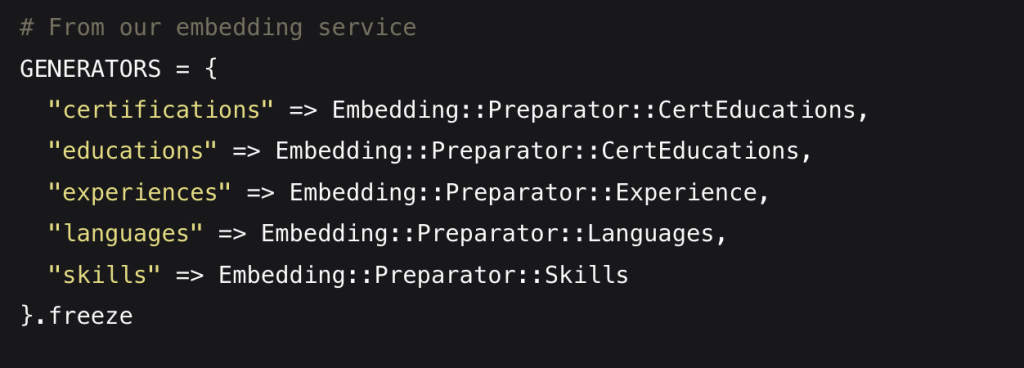
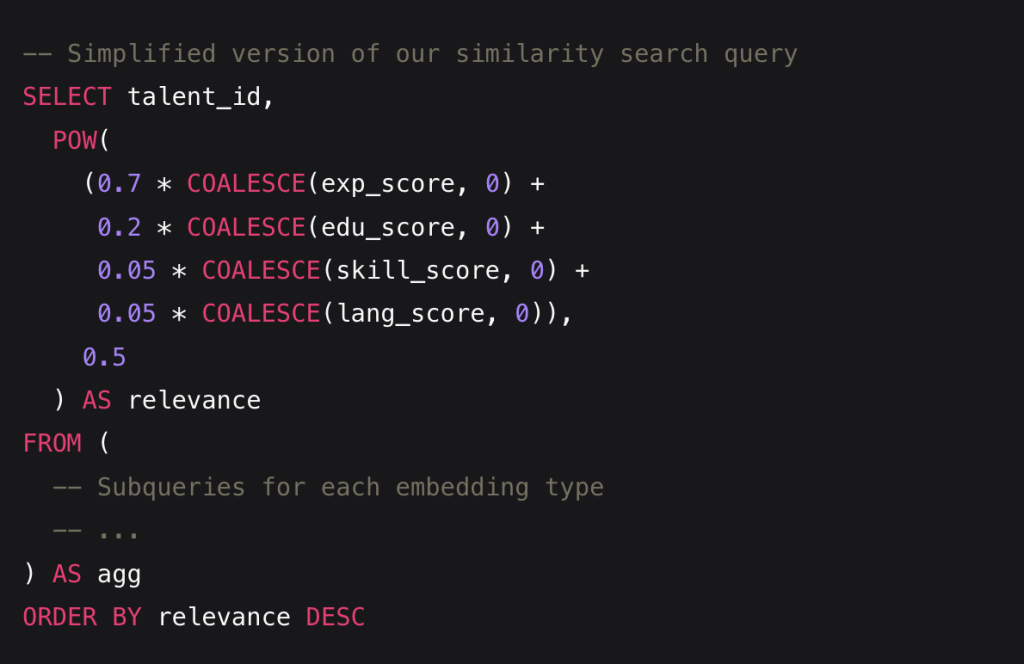
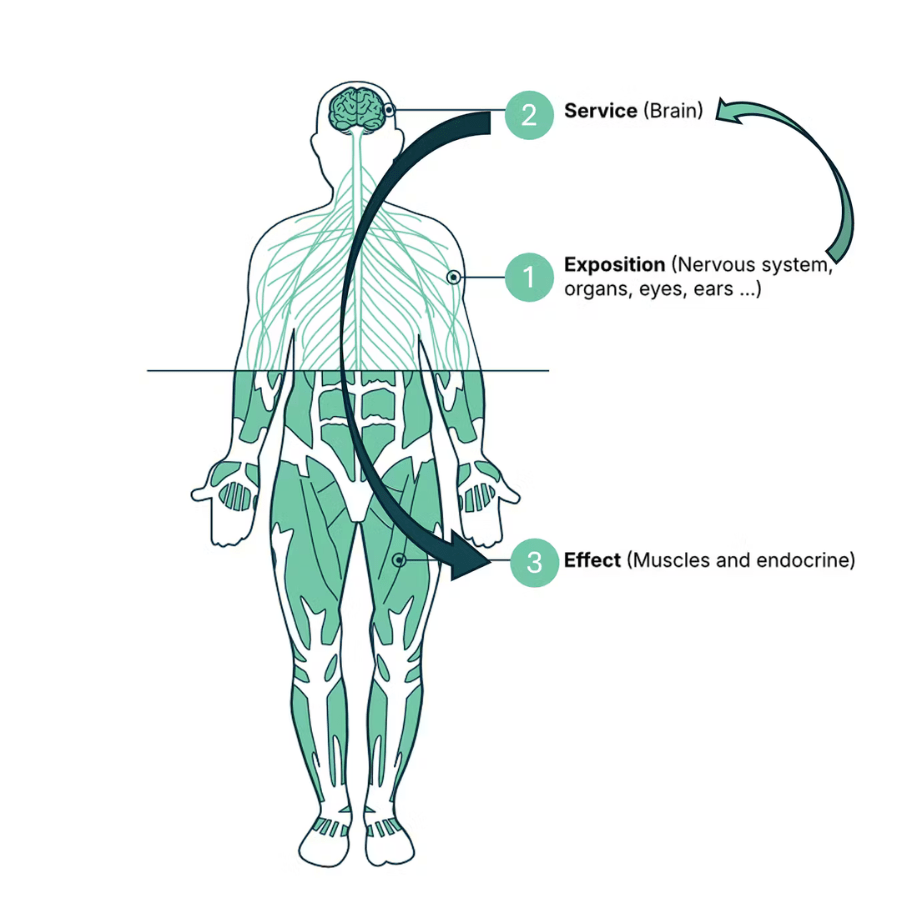
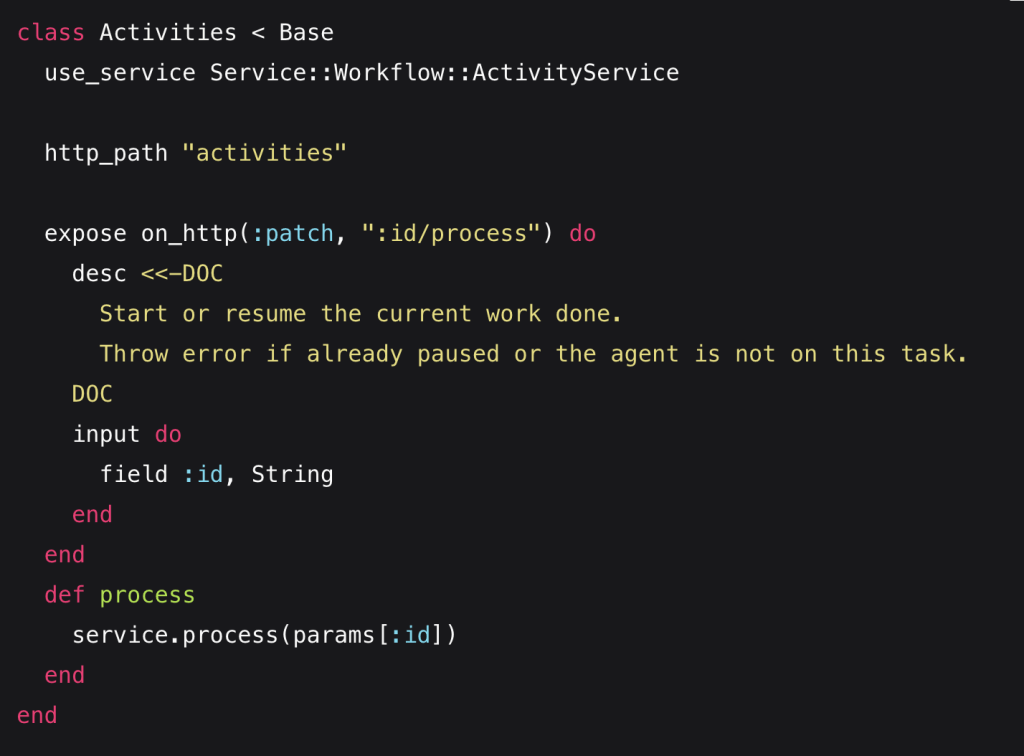
Our blog ESE Architecture: The Human Body of Software Design In previous articles, I’ve hinted at...
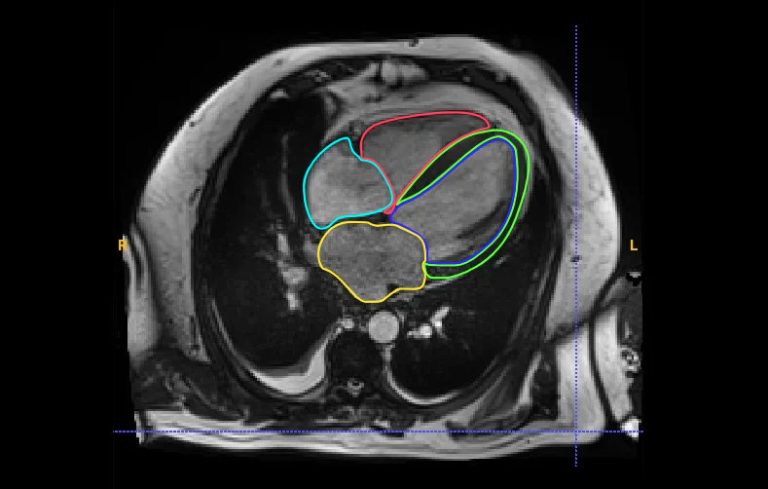
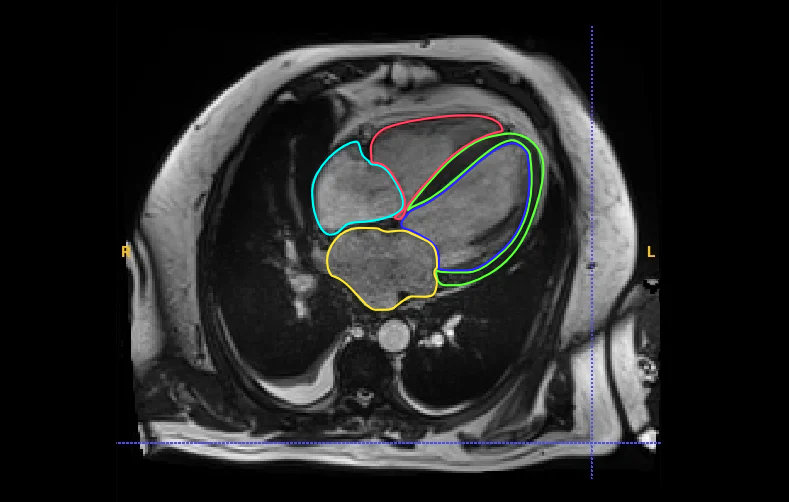
Our blog Standardizing Medical Imagery: Opportunities and Challenges in a Multimodal Landscape...
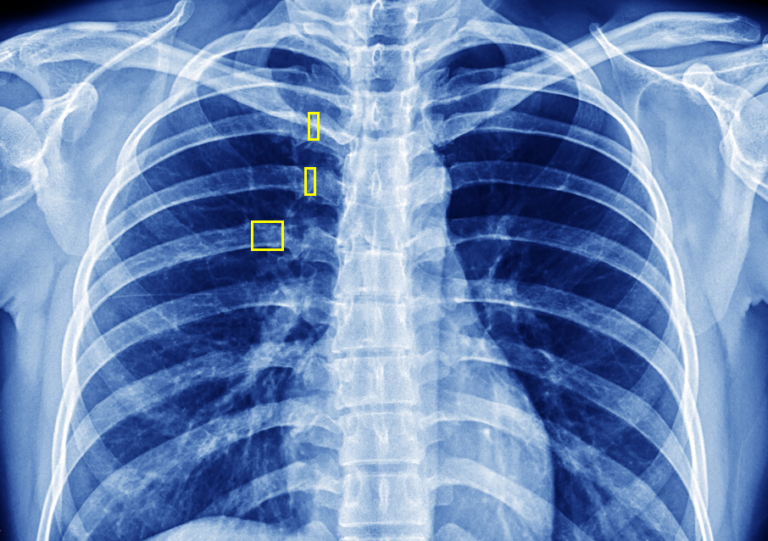
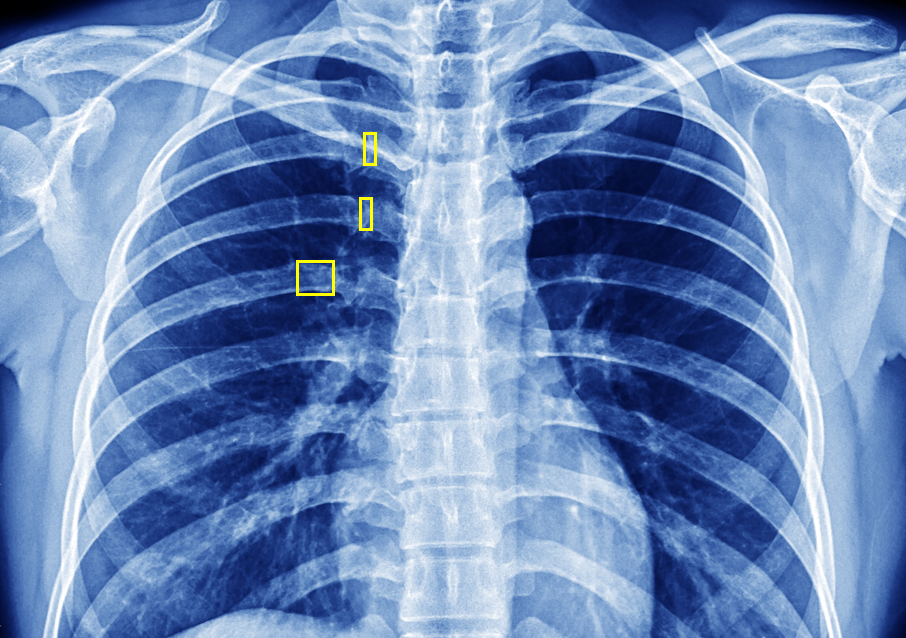
Our blog Identifying Rib Fractures on Frontal Chest X-rays: Clinical Relevance and Diagnostic...
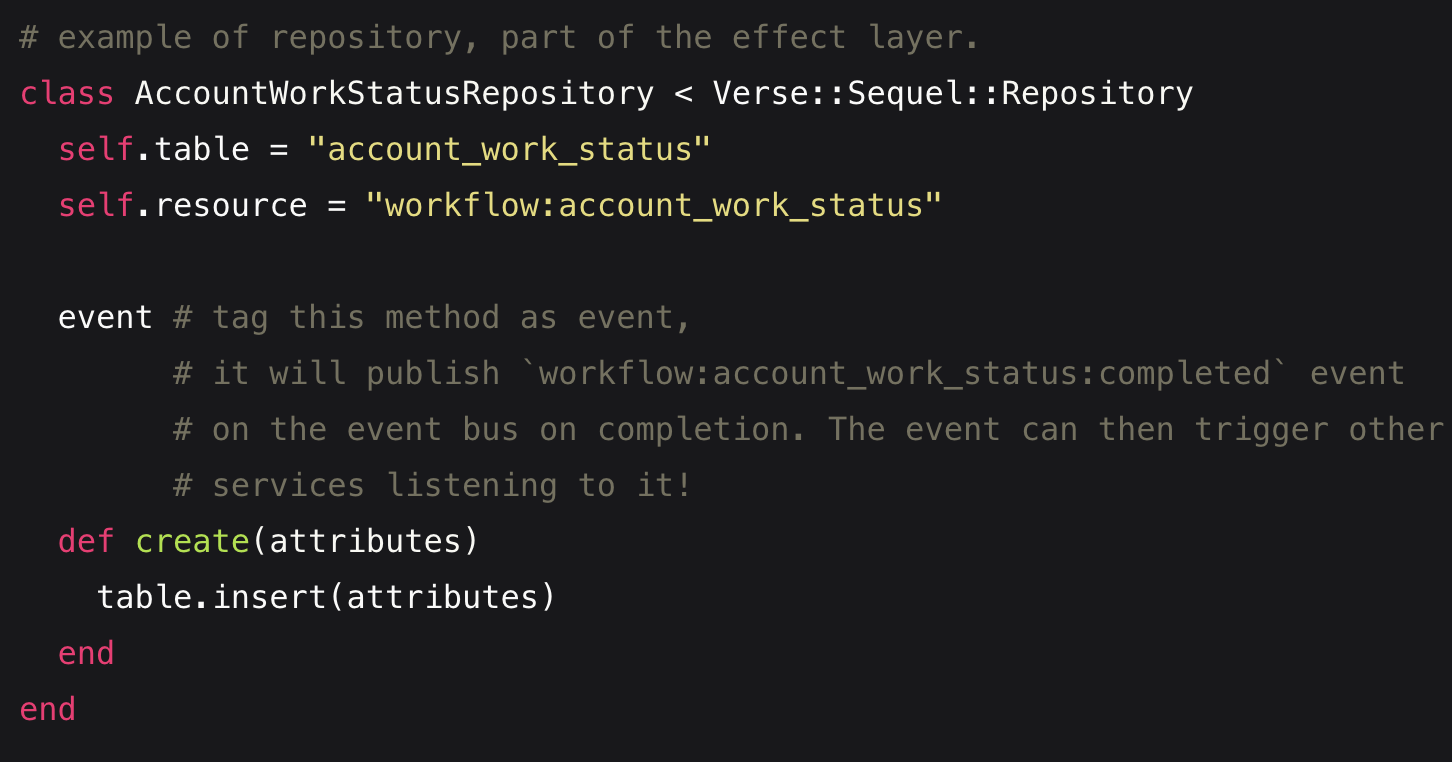
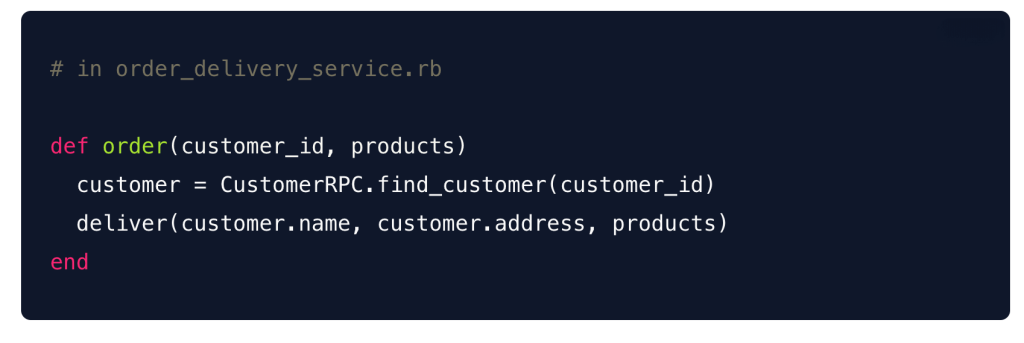
Our blog Event-Driven Microservice Architecture: Why We Chose It and How We Implemented It Welcome...

Our blog Data Annotation: The Secret Sauce of AI Vision 🔍 Ever wondered how AI learns to...

Our blog Migration from Rhymes to Pulse: Our Journey in Building a Better ERP System Hey there! I’m...