Event-Driven Microservice Architecture: Why We Chose It and How We Implemented It
Welcome to the second installment in our series on the architecture of Ingedata’s Pulse platform!
When we made the decision to move away from our previous platform, the first question we faced was, “What do we want to build?” Should we overhaul our tech stack, transitioning from Ruby to a language like Python or Go? Should we abandon the monolithic architecture and embrace the microservices trend?
Yacine
Chief Technical Officer
Before diving into these decisions, we needed to clarify the pain points we were addressing. By “pain points”, I’m not just referring to technical challenges but broader issues impacting our overall approach. Thanks to our previous platform, we have a clear understanding of our business requirements since the system is already operational and running.
The bigger question was about the non-functional qualities of our system and how to approach both the design and maintenance phases. Something built for decades, not for a few years.
Here are the key considerations we focused on:
Interoperability and API-First Design
Our previous platform was extensible, but not interoperable. While we could add modules and code in a structured manner, the system’s accessible endpoints were designed to meet the needs of the frontend application. Authorization and role management were handled at the endpoint level, with custom code filtering returned collections. If we wanted to integrate the application with other software, we would need to rewrite API endpoints and duplicate portions of the code.
For Pulse, we wanted a system that was fundamentally API-first, where the frontend would be just one of many clients utilizing these APIs. These endpoints should also be automatically documented to facilitate easier integration.
Maintainability and Flexibility
In any system, there’s a design phase where new software components and cutting-edge technologies are combined to build the application’s features. As the application matures and enters production, the focus shifts from feature development to refining and maintaining the platform. This includes reworking poorly designed code, handling edge cases, and adapting to an ever-changing business landscape.
New features often correspond with shifts in business paradigms, emphasizing the need for interoperability. For instance, if we decide to manage orders tomorrow (a feature not currently supported by our system), instead of creating a new module, we should be able to develop an entirely new platform that communicates seamlessly with Pulse. Rather than expanding the existing application, the goal is to connect multiple applications.
Resource Constraints and Knowledge Sharing
At Ingedata, we don’t have the vast resources of a company like Google, and our IT team can only grow so much. We place a high value on knowledge sharing and mentoring developers, which means we always maintain a portion of our development team as young, eager learners. While this approach fosters growth, it also means that the code produced isn’t always of the highest quality.
Agility and Resilience
Delivery speed is critical at Ingedata. We pride ourselves in being able to handle any customer project within 3 weeks. We need to be able to deploy changes quickly and respond to bugs with minimal delay. However, moving fast can sometimes mean breaking things, and with 500 employees relying on the system, downtime is not an option. One of our key goals was to design an application that could continue functioning even if certain parts of the system were down.
Considering all these factors, we decided to design our application as a microservice architecture with a twist: it’s event-driven.
The Advantages of Microservices
By breaking the application into multiple domains and databases, we make it easier for developers to quickly understand the specific domain they’re working on, even without prior knowledge. Instead of dealing with 150+ database tables, developers only need to focus on the 15 tables relevant to a specific service.
This approach also creates what I call a “contained mess.” If a young developer makes design mistakes while implementing new features, those mistakes are confined to the scope of the service/domain, making it easier to refactor the code later.
Our operations are cyclical, driven by batches of tasks we process for customers. We need a system that can scale up and down as needed. A monolithic approach would force us to scale everything simultaneously, which isn’t ideal. Microservices, on the other hand, allow us to scale specific domains as required. They also boot faster, which is a significant advantage when used with orchestration systems like Kubernetes. For example, while Rhymes (built on Rails) takes about 15 seconds to load and serve customers due to the extensive codebase, a Pulse service takes only 1.5 seconds.
Finally, microservices make it easier to adapt to changes in business. We can create new services to handle new features or shut down activities that no longer align with our goals. We have no qualms about discontinuing code if we find third-party software that does the job better and more cost-effectively.
The Event-Driven Approach
When building microservices, it’s crucial to determine how different components will interact. There’s no point in adopting a microservice architecture if everything is tightly coupled. Initially, we considered using RPC-based communication, such as HTTP or gRPC, for internal service communication. However, this approach introduces tight coupling. If one service needs to query another and the dependent service is down, it could create a cascade of errors.
Additionally, RPC calls can lead to transaction integrity issues. For example, if Service A needs to update data in Services B and C, and B succeeds while C fails, A might need to revert its changes, but B has already committed them to the database.
To address these challenges, we opted for an event-driven architecture. Unlike RPC calls, services communicate asynchronously by emitting events after changes are made. This approach reverses the dependency links between services, making each service responsible for its own state. Instead of Service A querying Service B for information, Service A listens to events emitted by Service B and updates its state accordingly.
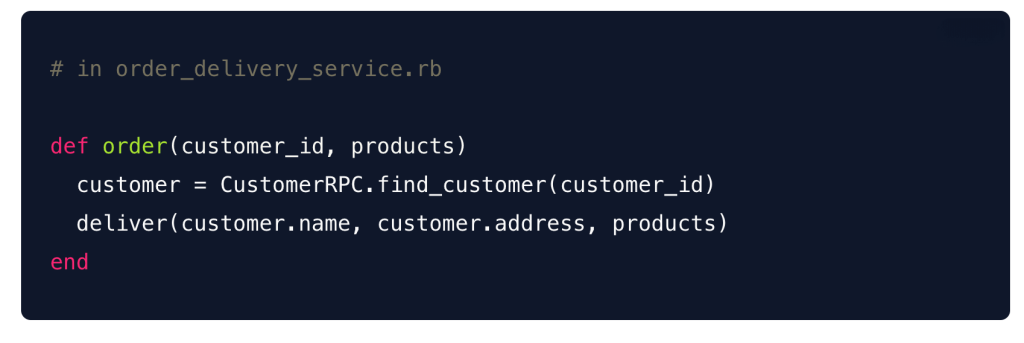
Here’s an example:
Let’s say the OrderDelivery service needs information about a customer’s address from the Customer service. With an RPC-based approach, the code might look like this:
Using an event-driven approach and our custom-built framework, Verse, the code would look like this:
Yes, it’s a bit more complex and requires additional effort, but we’ve effectively decoupled the two services. Now, whenever a customer is created in the Customer service, a corresponding record is created in the OrderDelivery service. If the customer’s name or address is updated, OrderDelivery tracks those changes. Even if the Customer service goes down, OrderDelivery can still handle orders. Messages are sent through a streaming service, ensuring that if OrderDelivery is temporarily down, it can replay stored events and catch up when it comes back online.
It also simplifies scaling! Each service instance can manage a specific number of concurrent requests at a time (in our case, 5 per instance/CPU). With an RPC-based approach, if the Customer service begins to experience delays in responding, our Kubernetes orchestrator would scale up not just the Customer service, but also the OrderDelivery service. This happens because OrderDelivery’s order method would only be as fast as the Customer#find_customer API call, creating a bottleneck. This tight coupling can lead to significant challenges when trying to diagnose and resolve performance issues later on.
With the decision to adopt an Event-Driven architecture settled, the next question was which tech stack to use. We explored transitioning to Go or Python and came close to choosing FastAPI, which met many of our requirements and offered strong integration with AI frameworks. However, we ultimately decided to stick with Ruby and develop our own framework.
Our reasoning was multifaceted: we could leverage existing knowledge, Ruby’s ecosystem for web development remains highly competitive, and we genuinely prefer Ruby’s syntax, which, while similar to Python, offers a more enjoyable developer experience—particularly with its capacity for building DSLs.
As for Go, while it’s known for its performance, our specific needs didn’t justify the switch. We prioritized a language that resonates with our team’s expertise and offers a positive, engaging development environment.
With our decision made, it was time to build our framework. We put in extra effort and began constructing it using the ESE (Exposition-Service-Effect) stack, departing from the more traditional MVC 3-tiered setup. But that’s a story for another time—stay tuned for our next article, where we’ll dive into the details!