How do you find the perfect candidate for a job opening when traditional keyword matching falls short? How can you match skills and experiences semantically rather than lexically? This article explores our journey building a sophisticated talent matching system using vector embeddings, explaining both the technical challenges we faced and the solutions we implemented.
The Challenge of Talent Matching
In traditional recruitment systems, finding candidates often relies on keyword matching – searching for exact terms like “Python” or “Project Manager” in resumes. This approach has significant limitations:
Vocabulary Mismatch: A resume might mention “Django” but not explicitly say “Python”
Context Insensitivity: Unable to understand that “led a team of 5 developers” indicates leadership skills
Synonym Blindness: Missing that “software engineer” and “developer” are essentially the same role
Qualification Nuance: Difficulty distinguishing between someone who “used React” versus someone who “built and maintained large-scale React applications”
We needed a system that could understand the semantic meaning behind job requirements and candidate qualifications, not just match keywords.
Our Solution: Vector Embeddings and Semantic Search
Our approach leverages AI-powered vector embeddings to create a semantic search system that understands the meaning behind words, not just the words themselves. Here’s how it works:
Understanding Embedding Space
Vector embeddings are numerical representations of text in a high-dimensional space where semantic similarity is captured by vector proximity. In simpler terms:
Each piece of text (a job description, a skill, an experience) is converted into a vector of numbers
Similar concepts end up close to each other in this “embedding space”
We can measure similarity between concepts by calculating the distance between their vectors
For example, in this space, “software engineer” and “developer” would be close together, while both would be further from “marketing specialist.”
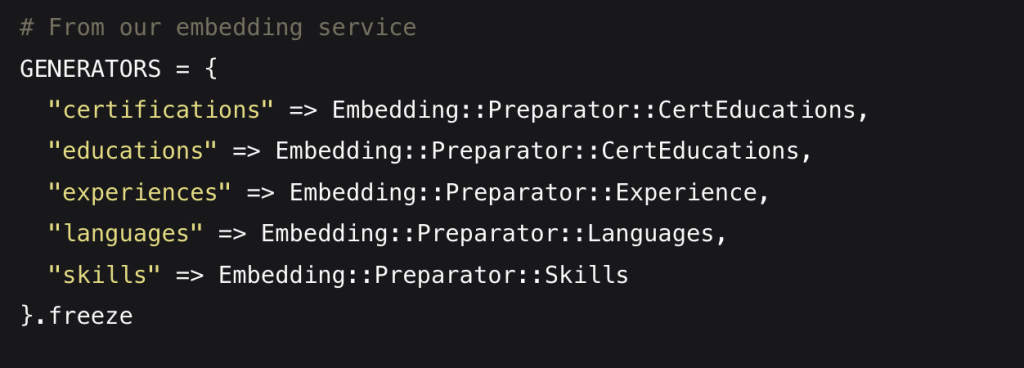
Multiple Embedding Points for Comprehensive Matching
A key insight in our implementation is that a single embedding for an entire resume is insufficient. Different aspects of a candidate’s profile need different types of semantic understanding:
Experience Embeddings: Capture work history, roles, and responsibilities
Education Embeddings: Represent academic background and qualifications
Skills Embeddings: Encode technical and soft skills
Language Embeddings: Represent language proficiencies
Each of these aspects is embedded separately, allowing for more nuanced matching. For example:
This multi-embedding approach allows us to:
Weight different aspects differently (e.g., giving more importance to experience than education)
Match candidates who might excel in one area even if they’re weaker in others
Provide more granular control over the matching algorithm
From Resume to Embeddings: The Processing Pipeline
When a resume is uploaded to our system, it goes through a sophisticated processing pipeline:
Resume Extraction: We use AI to extract structured data from the resume document
Text Normalization: Each component (experience, education, etc.) is normalized into a standard format
Embedding Generation: Each component is converted into a vector embedding
Storage: The embeddings are stored in PostgreSQL with pgvector extension
The embedding generation process uses carefully crafted prompts to ensure consistent, high-quality embeddings:
## Instructions You are provided with details for one candidate experience record, which includes the following: – If any content is not in English, always translate into English. – Ignore any duration or date information. – Introduction should always start with “The candidate” – Generate a standardized, descriptive text that summarizes this work experience. – Always explain the candidate’s position in a clear and concise manner if you cannot do nothing. – Your output should be one or two sentences that clearly explain the candidate’s role and responsibilities in a narrative format. … more directives …
Notice how we explicitly ignore duration information in our prompts? This is intentional – we found that including years of experience in embeddings actually reduced matching quality by overemphasizing tenure rather than relevance of experience.
Query Processing: Matching Jobs to Candidates
When a user searches for candidates, a similar process occurs:
Query Parsing: The search query is analyzed to extract key components (required experience, skills, education, languages)
Query Embedding: Each component is embedded into the same vector space as the resume components
Similarity Search: We find the closest matches for each component
Weighted Combination: Results are combined with appropriate weights for each component
Ranking: Candidates are ranked by overall relevance
Our query processing uses a specialized prompt that ensures consistent interpretation:
You are an AI system that processes talent queries and extracts key details into a JSON-formatted string. Your output must include exactly four keys: `”experience”`, `”language”`, `”education”`, and `”skills”`. Follow these instructions: 1. **Output Format:** IMPORTANT: The final output format must be in English only, even when the initial input is not in English. The final output must be a single JSON string (without extra formatting) as shown below: ”'{ “title”: , “experience”: , “language”: , “education”: , “skills”: }”’ … more directives below …
Optimizing Performance with PostgreSQL Vector Extensions
Storing and querying vector embeddings efficiently is crucial for system performance. We leverage PostgreSQL with vector extensions (specifically pgvector) to handle this specialized data type.
Vector Indexing for Fast Similarity Search
To make similarity searches fast, we use specialized HNSW (Hierarchical Navigable Small World) indexes:
— Example of how we create vector indexes in our migrations
CREATE INDEX embeddings_experiences_embedding_idx ON embeddings_experiences USING hnsw (embedding vector_ip_ops);
We specifically chose HNSW over other index types like IVF-Flat because it offers significantly better performance for our use case. HNSW builds a multi-layered graph structure that enables efficient approximate nearest neighbor search, dramatically reducing query times.
Additionally, we use the dot product (vector_ip_ops) as our similarity operator rather than cosine similarity. While cosine similarity is often the default choice for text embeddings, we found that using the dot product provides better performance without sacrificing accuracy in our normalized embedding space.
These optimizations dramatically speed up nearest-neighbor searches in high-dimensional spaces, making it possible to find the most similar candidates in milliseconds rather than seconds.
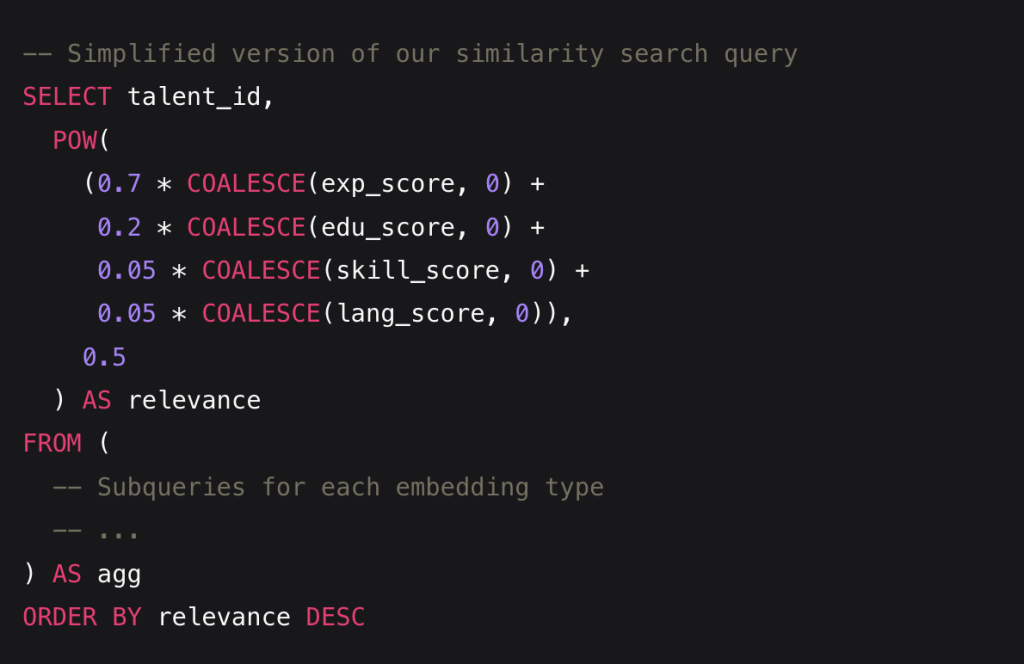
Optimized Query Structure
Our query structure is carefully optimized to balance accuracy and performance:
Notice the weighting factors: we give 70% weight to experience, 20% to education, and 5% each to skills and languages. These weights were determined through extensive testing and reflect the relative importance of each factor in predicting candidate success.
Challenges and Solutions
Building this system wasn’t without challenges. Here are some key issues we faced and how we solved them:
Challenge 1: Single Embedding Limitations
Problem: Our early version used a single embedding per talent, which created misleading similarity measurements. For example, two candidates with the same years of experience in completely different fields would appear more similar than they should.
Solution: We moved to multiple embeddings per talent (experience, education, skills, languages), each focused on a specific aspect. This approach recognizes that the embedding space isn’t perfectly calibrated for talent search – it’s a general semantic space where “distances” don’t always reflect business-relevant distinctions. By separating different aspects and weighting them appropriately, we can better control how similarity is calculated.
For example, with separate embeddings, a software developer with 5 years of experience and a marketing specialist with 5 years of experience would no longer appear artificially similar just because they share the same tenure. Instead, their experience embeddings would correctly place them in different regions of the semantic space.
A typical implementation might use an event-driven approach:
Challenge 2: Embedding Quality and Consistency
Problem: Early versions produced inconsistent embeddings, especially for similar experiences described differently.
Solution: We developed standardized prompts that normalize the text before embedding, focusing on roles and responsibilities while ignoring potentially misleading details like years of experience.
Challenge 3: Performance at Scale
Problem: As our database grew, query performance degraded.
Solution: We implemented:
Optimized HNSW vector indexes with carefully tuned parameters
Dot product similarity operations for faster computation
Query limits to focus on the most promising candidates first
Caching of common queries
Challenge 4: Handling Multiple Languages
Problem: Our talent pool includes resumes in multiple languages, but we use an English-only embedding model for optimal performance.
Solution: Rather than using less accurate multilingual embedding models, we translate all content to English during the normalization process before embedding. This approach allows us to use a high-quality English-specific embedding model while still supporting our international talent pool. The translation step is integrated directly into our prompt templates:
## Instructions You are provided with details for one candidate experience record, which includes the following: – If any content is not in English, always translate into English. …
This standardized translation ensures consistent semantic representation regardless of the original language, maintaining high-quality embeddings across our entire database.
Challenge 5: Database Quality Issues
Problem: Many talents in our database had non-descriptive or vague experience entries like “Data entry specialist” or “Outsourcer specialist” which polluted search results by creating misleading embeddings.
Solution: We implemented a comprehensive database cleanup process:
Identified talents with vague or non-descriptive experiences
Added more detailed information where possible through follow-up data collection
Removed experiences that lacked sufficient detail and couldn’t be improved
Implemented quality checks for new data entry to prevent similar issues
This data quality initiative significantly improved our matching results by ensuring that all embeddings were generated from meaningful, descriptive content.
Challenge 6: Balancing Precision and Recall
Problem: Early versions either returned too many irrelevant candidates or missed qualified ones.
Solution: We fine-tuned our similarity thresholds and implemented a weighted scoring system that combines multiple embedding types, achieving approximately 95% confidence in our top results.
Results and Impact
The implementation of our vector embedding-based talent matching system has transformed our recruitment process:
Improved Match Quality: Our system finds semantically relevant candidates even when their resumes don’t contain the exact keywords
Faster Candidate Discovery: Recruiters find suitable candidates in seconds rather than hours
Reduced Bias: By focusing on semantic meaning rather than specific terms, we’ve reduced some forms of unconscious bias
Higher Placement Success: The quality of matches has led to higher success rates in placements
Simplified User Experience: HR staff can now search for candidates by typing natural language queries (e.g., “experienced Python developer with cloud expertise”) instead of filling out complex forms with specific keywords and filters. This intuitive interface has dramatically increased adoption and satisfaction among recruiters.
Conclusion
Our journey building a semantic talent matching system demonstrates the power of vector embeddings for understanding the nuanced relationships between job requirements and candidate qualifications. By embedding different aspects of resumes separately, optimizing our database for vector operations, and carefully tuning our matching algorithms, we’ve created a system that consistently finds the right candidates with approximately 95% confidence.
The approach we’ve taken – using multiple embedding points, ignoring potentially misleading information like years of experience, and leveraging PostgreSQL’s vector capabilities – has proven highly effective for talent matching. These same principles could be applied to many other domains where semantic understanding is more important than keyword matching.
Have you implemented vector search in your applications? We’d love to hear about your experiences and challenges. Reach out to our team to share your thoughts or learn more about our implementation.
This article describes a feature of the Pulse platform, which is the system powering Ingedata’s business. Stay tuned for more insights into how we’re using cutting-edge technology to solve real business problems.