Expert Data Workflows for High-Stakes Industries
IngeData builds computer-vision data pipelines designed for strict standards and high-stakes use. We ensure your AI is grounded in clean, reliable, regulation-ready data.

Turn Raw Data into Model-Ready Datasets
We improve model performance by enriching, annotating and structuring high-quality training data with domain-specific methodologies.

Industry 5.0
Semantic Segmentation

Industry 5.0
Polygons

Industry 5.0
Point Cloud

Industry 5.0
Cuboids (3D Boxes)

Industry 5.0
Bounding Boxes

Earth Observation
Landmark Positioning

Earth Observation
Bounding Boxes

Earth Observation
Polygons
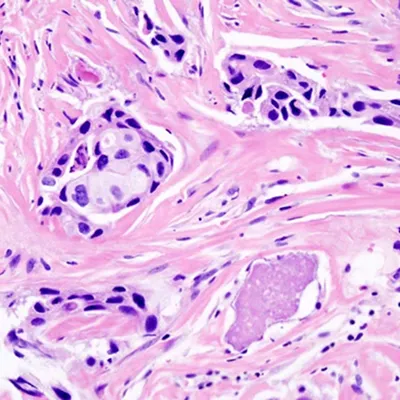
Healthcare
Pathology
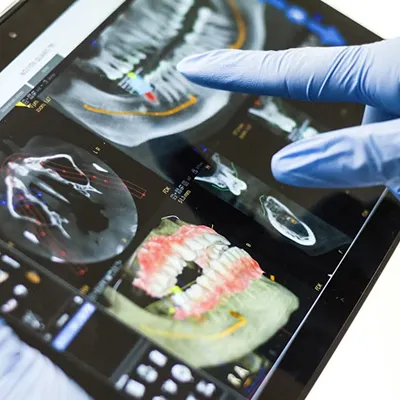
Healthcare
Dental
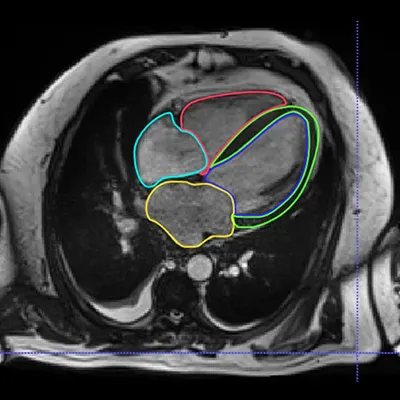
Healthcare
3D Segmentation

Healthcare
Regions of Interest
Healthcare
Radiology




IngeData is a great, effective partner and I’m glad we decided to work with them. They helped us set up a scalable annotation process with a hybrid team of radiologists and technologists. What we previously handled in-house simply wasn’t scalable — IngeData made the process much easier.
Steven Rankin
Chief Strategy Officer
Enlitic

IngeData's team of expert radiologists delivered precise, consistent annotations across more than 600 cases, with impressive efficiency. This project represents a major step forward in developing robust, clinically relevant AI models for breast cancer detection.
Jakob Wasserthal
Research Scientist
University Hospital Basel (TotalSegmentator)

The collaboration with IngeData allowed XXII Group to reach a high level of attractivity towards data scientists, since we are now able to provide them with abundant annotated data. These annotations are delivered by IngeData through our dedicated team of 20 annotators working hand in hand with our team. Considering the very tight market conditions on the data scientists market, this is a considerable business result for us to grow fast.
William Eldin
CEO
XXII Group

IngeData brought great project management skills to our project. I was a bit worried about our tight deadlines, but the quality of the project architecture secured the annotation workflows and ensured swift deployment and delivery. We could use IngeData’s annotations to retrain our AI models and hit our model accuracy targets.
Marion Rosenstiehl
Programme & Product Manager
SUEZ

IngeData does a really good job. It’s great how we set a labelling process to segment and label our satellite images. They built a specialised team of annotators for photo interpretation and my data labelling pipeline is now more efficient and qualitative. It’s almost like having my own team of annotators. I just choose the image dataset and add it to Ingedata’s annotation backlog. Thanks, guys!
Renaud Allioux
Chief Technology Officer
Preligens

We have successfully partnered with Ingedata on multiple projects covering hundreds of CT scans. By setting up a team of radiologists with project managers in the long run, we have achieved very high quality and swift execution of the projects. This setup builds trust and alleviates a lot of the burden during training and ramp up, with constant feedback helping to improve the annotation set up. We have obtained consistent and clean results both in complex protocols and precise segmentations.
Benjamin Renoust
Data and Knowledge Coordinator
Median Technologies
Strengthen Data Workflows Across High-Risk Domains
Explore how IngeData powers AI across highly regulated industries.





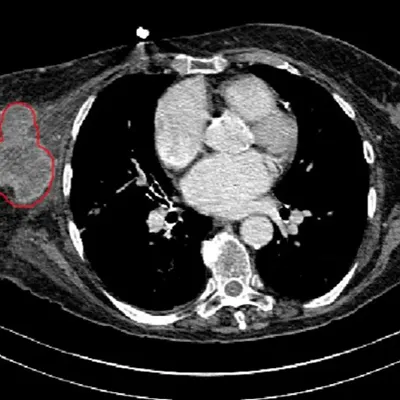
Read All Case Studies
A Partner In Data Excellence
Combining Domain Insight with Human Expertise to Build Safe and Compliant Datasets
Human-Led Domain Expertise
All projects are supported by domain specialists, from doctors and radiologists in Healthcare to geospatial experts in Earth Observation, ensuring annotations reflect real-world insight.

Compliance by Design
GDPR, and ISO compliance are embedded in our processes, so your datasets are secure, audit-ready and regulator-proof.

Platform-driven Delivery
Our projects run on a secure platform with workflow customisation, live dashboards and KPI monitoring, giving you transparency and control at every stage.

Our Team In Action









Meet The Team Driving Our Data Workflows
Each domain is led by industry practitioners who bring the contextual expertise.

Radiologist
Scarlet Erngil Macalalag
A longstanding collaborator since Ingedata’s very first medical project, driving multiple successful projects and offering dependable support throughout

Radiologist
Leandro Tabao
Lead radiologist across major projects, supporting feasibility and specification analysis and consistently delivering top-tier annotation performance

Radiologist
DR Balbuena Viojan
A trusted Ingedata collaborator for over four years, known for accuracy, reliability, and a consistently supportive attitude






More About IngeData